This is the last post in the series on myths about quantum computing.
One of the most exciting things about quantum information is quantum teleportation—the ability to transmit quantum data by sending only classical bits. Superdense coding is another surprising protocol which lets you transmit two classical bits by sending only one qubit.
It is often mistakenly believed that these two features of quantum information do not have a classical equivalent. The goal of this post is to explain why this is not the case, and to clarify other related misconceptions.
Bell states
Let us first briefly discuss some simple facts that are useful for explaining how quantum teleportation works. Let 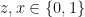

This is known as Bell basis. One can prepare 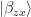
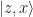
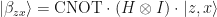
One of the most important properties of Bell states is that any Bell state can be mapped to any other by applying local Pauli matrices on only one of the systems:

Quantum teleportation
The setting for quantum teleportation is as follows. Assume that Alice has a single-qubit quantum state 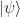
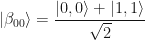
known as EPR pair, shared between them. Here is a schematic diagram of how quantum teleportation works:

Here “Bell” denotes the measurement in the Bell basis whose outcomes are classical bits z and x, and 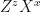
Quantum teleportation works because of the following identity:
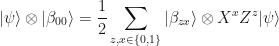
which holds for any single qubit state 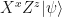
The usual argument why quantum teleportation is surprising, is that it allows to transmit a quantum state
Classical teleportation
What is the classical equivalent of the above procedure? Let us first set up some terminology and notation. Since we will be dealing with probability distributions, let
![\mu = \dfrac{1}{2} [0] + \dfrac{1}{2} [1]](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+%5Cdfrac%7B1%7D%7B2%7D+%5B0%5D+%2B+%5Cdfrac%7B1%7D%7B2%7D+%5B1%5D++&bg=ffffff&fg=111111&s=0&c=20201002)
denote the uniform distribution over {0,1}. Similarly, let
![\beta = \dfrac{1}{2} [0,0] + \dfrac{1}{2} [1,1]](https://s0.wp.com/latex.php?latex=%5Cbeta+%3D+%5Cdfrac%7B1%7D%7B2%7D+%5B0%2C0%5D+%2B+%5Cdfrac%7B1%7D%7B2%7D+%5B1%2C1%5D++&bg=ffffff&fg=111111&s=0&c=20201002)
be the classical version of the EPR state 
Intuitively, one should think of probability distributions as a way of describing a coin that has been flipped and (without looking at it) put inside a sealed envelope. Note that one can perform operations on such coin, even though its exact state is not known. For example, by flipping the envelope around one can perform the logical NOT. One could also imagine some more complicated procedures for performing joint operations on two coins in a joint unknown state.

We will use the term pbit to refer to a probabilistic bit that describes a coin inside the envelope. Note that a pbit has one degree of freedom. However, once the envelope has been opened, the state of the coin becomes certain, i.e., either [0] or [1], so we will describe it by a deterministic bit or dbit. Note that this is analogous to how measurements work in the quantum case, except that in the classical case there is only one measurement basis—the standard basis.
Now we are ready to describe the classical teleportation. Our task is the following: we would like to transmit one pbit by sending one dbit. In other words, we want to transmit one degree of freedom per one classical bit being sent, just as in the quantum case.
At first, this might seem trivial—can’t we just send the bit over and be done? Unfortunately, not. Recall that we want to transmit a pbit or an “unobserved coin”, but we are allowed to send only a dbit. In other words, your envelope will always be opened and its content revealed, just as if you were a journalist sending an e-mail from China. Let us depict this situation with the following diagram:

Here the dark pipe represents a pbit in state 
To make this scheme work, we will use a shared resource between Alice and Bob as in the quantum case. A natural classical equivalent of the EPR state 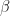

This indeed gives the correct result, since the original pbit essentially gets XORed with the same value twice. Intuitively, one can think of it being transmitted “back in time” through the black pipe that represents
Quantum superdense coding
Quantum superdense coding is the dual protocol of quantum teleportation (this can be made more precise by considering coherent communication). It allows to send two classical bits by transmitting a single qubit and consuming one shared EPR pair.
Initially Alice and Bob share an EPR state

Quantum superdense coding works because of the following identity:
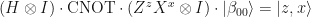
This immediately follows from the properties of Bell states discussed above. Since all Bell states are maximally entangled, their reduced states are completely mixed, so the transmitted qubit contains no information about the two encoded classical bits z and x.
Classical “supersparse” coding
Classical superdense coding is very similar to classical teleportation, except the roles of dbit and pbit are reversed, i.e., Alice wants to transmit a dbit by sending a pbit. This seems to be even simpler than teleportation, since we are given more resources and asked to perform a simpler task! In fact, there is nothing “superdense” about this task, as it only wastes resources. In this sense it would be more appropriate to call it “supersparse” coding!
The only catch is that for complete analogy with the quantum case, the transmitted pbit should be uniformly random, so that a potential eavesdropper could learn nothing about the original message. Here is a protocol that achieves the task of transmitting a dbit b in the desired way:

Note that the only difference between this picture and the one for classical teleportation is the color of pipes.
Conclusion
Quantum teleportation should not seem more surprising than the classical one, since in both cases one degree of freedom is transmitted per one classical bit being sent. The only quantitative difference is a factor of two in the amount of resources consumed: one ebit is consumed for sending two degrees of freedom in the quantum case versus one shared random bit per single degree of freedom in the classical case. Recall that we observed the same factor-of-two difference in the case of the amount of information needed to specify a quantum versus a classical probabilistic state within the exponential state space.
Thus, given the existence of a classical equivalent, quantum teleportation should not seem too surprising. At least, no more than by a factor of two!
p.s. As Matthew Leifer has pointed out to me, these and many other analogies between quantum entanglement and secret classical correlations have been described in the paper “A classical analogue of entanglement” by Daniel Collins and Sandu Popescu.
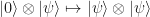
 and
and 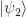 be two quantum states, and assume that U is a unitary operation that implements the desired transformation. Then
be two quantum states, and assume that U is a unitary operation that implements the desired transformation. Then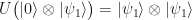


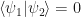 or
or 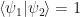 . This means that using a unitary transformation we can only copy states from an orthonormal set. However, the set of all quantum states is not orthonormal, so there is no unitary transformation that would copy an arbitrary unknown quantum state.
. This means that using a unitary transformation we can only copy states from an orthonormal set. However, the set of all quantum states is not orthonormal, so there is no unitary transformation that would copy an arbitrary unknown quantum state. 
 operation!) In probabilistic classical computing the set of allowed transformations are those that map probability distributions to probability distributions. Such transformations are called
operation!) In probabilistic classical computing the set of allowed transformations are those that map probability distributions to probability distributions. Such transformations are called 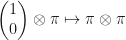



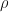 be a mixed quantum state on system
be a mixed quantum state on system  . We say that a pure quantum state
. We say that a pure quantum state 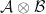 is a purification of
is a purification of 
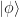 are two purifications of
are two purifications of 
 that acts only on system
that acts only on system  .
.
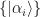 and
and  on systems
on systems  and
and 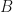 , respectively, and a probability distribution
, respectively, and a probability distribution  .
.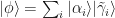
 are some arbitrary (non-normalized) vectors. Then we have
are some arbitrary (non-normalized) vectors. Then we have

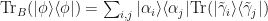

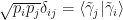
 are pairwise orthogonal and
are pairwise orthogonal and  (it could happen that
(it could happen that  for some
for some  , but this is not a problem). Equivalently, this equation says that we can find an orthonormal basis
, but this is not a problem). Equivalently, this equation says that we can find an orthonormal basis  such that
such that  . Then we see that
. Then we see that 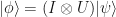 , where
, where  is the unitary change of basis from
is the unitary change of basis from 